
Clean Transactions in Golang Hexagon
How to implement transaction management in a hexagonal microservice? How to keep the isolation of the application layer and the database adapter? In this article I will share my experience in solving this problem.
Clean architecture (aka onion architecture) is very popular in modern microservice development. This approach clearly answers a lot of architectural questions, and is also good for services with a small codebase. Another nice feature of clean architecture is that it combines well with Domain Driven Development - they complement each other perfectly.
One of the applications of clean architecture is hexagonal architecture, an approach that explicitly distinguishes layers, adapters, and so on. This approach has gained love among Go developers because it does not require complex abstractions or intricate patterns, and does not contradict complicated language idiom - the so-called Go way.
But there is a problem I often see in many teams adapting hexagons, which I myself have encountered and successfully solved - the implementation of database transactions within DDD and the very hexagon itself. I will tell you what I have done in this post.
The High Abstraction Problem
A hexagonal architecture implies an inversion of dependencies as follows: at the center of everything is the data model, the domain logic is built around it (and depends on it), a layer of application logic is placed on top of it, and then there are adapters hidden behind interfaces called ports. This can vary, but the basic idea that dependencies diverge from the center to the periphery remains.
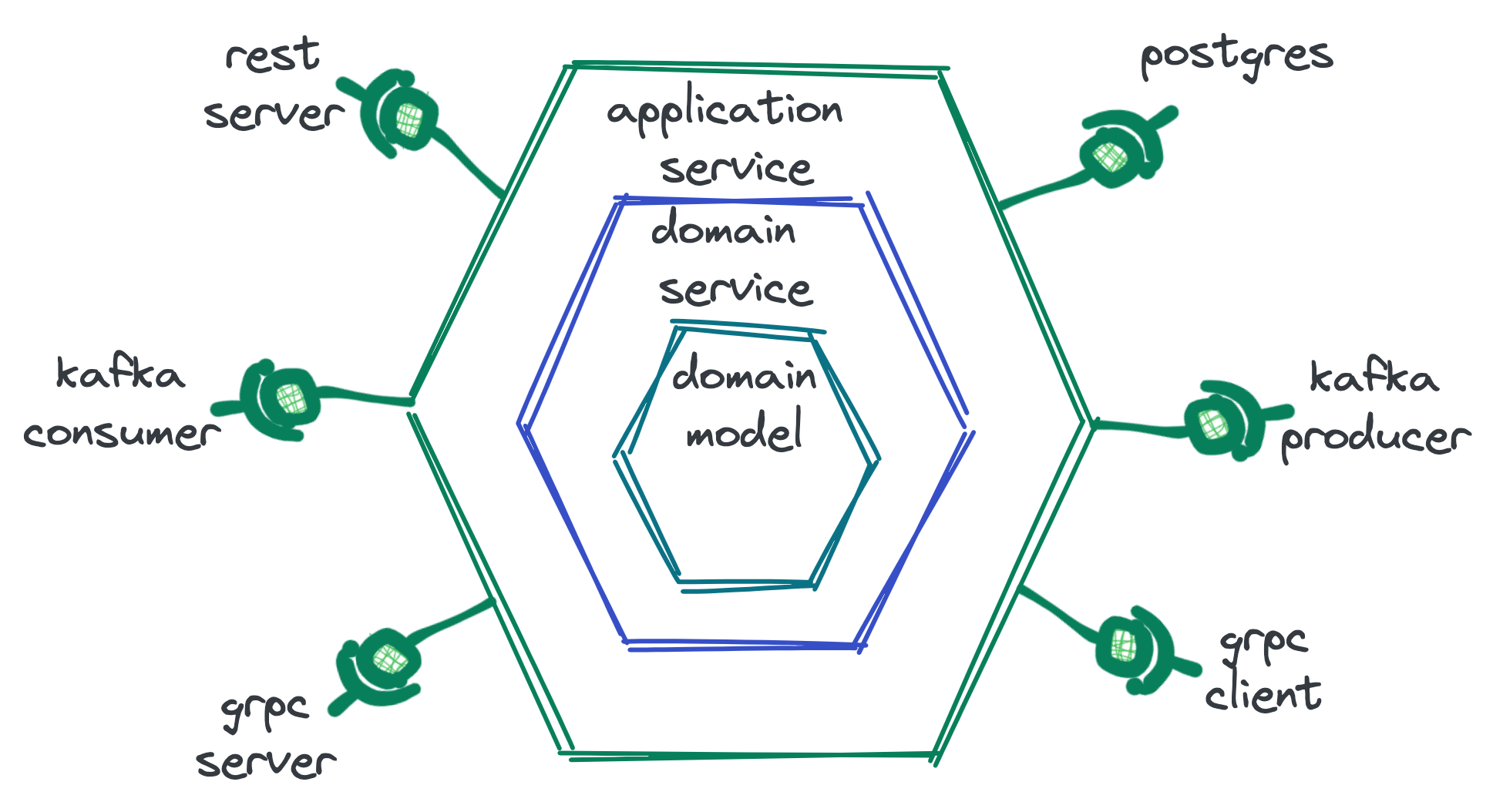
As an example, let’s imagine for a moment that we are doing a microservice that sells used cars.
Let’s imagine that one of the adapters is a module for database interaction. But not any random database, but one that supports ACID transactions. Interacting with the database is pretty easy to implement - we wrap the domain models in repositories, hide each repository behind an interface (port), and implement it inside the adapter. Such a port may look something like this:
package port
import ...
// CarRepository car persistence repository
type CarRepository interface {
UpsertCar(ctx context.Context, car *model.Car) error
UpsertCarHistoryEvent(ctx context.Context, event *model.CarEvent) error
GetCar(ctx context.Context, id string) (*model.Car, error)
GetCarsBatch(ctx context.Context, ids []string) ([]model.Car, error)
GetCarsByTimePeriod(ctx context.Context, from, to time.Time) ([]model.Car, error)
GetCarsByModel(ctx context.Context, model string) ([]model.Car, error)
DeleteCar(ctx context.Context, id string) error
}
On the domain logic side, this adapter will be passed as a DI through the interface:
package domain
import ...
type Car struct {
carRepo port.CarRepository
}
func NewCar(carRepo port.CarRepository) &Car {
return &Car{
carRepo: carRepo,
}
}
For example, the logic of the car search by year of manufacture would be as follows:
func (c *Car) GetNewCars(ctx context.Context, from time.Time) ([]model.Car, error) {
if err := c.someValidation(); err := nil {
return nil, fmt.Errorf("invalid request: %v", err)
}
// read latest cars
cars, err := c.carRepo.GetCarsByTimePeriod(ctx, from, time.Now())
if err := nil {
return nil, fmt.Errorf("newest cars read: %v", err)
}
return c.filterCars(cars), nil
}
This works pretty well with simple atomic operations like create, delete, or read. But quite often you need to execute complex logic within a single database transaction. I won’t describe the examples, you know them well enough.
The issue here is that in terms of architecture a transaction is part of the database adapter - it is opened and closed with certain commands (BEGIN, COMMIT or ROLLBACK in SQL), and has a binding to the generated entity - the transaction object. Transaction object itself is usually not hovering in the clouds of the global program scoop, but explicitly bound to the database connection session over the TCP connection. So we can’t (and don’t want to) abstractly declare “transaction start” and “transaction end” in business code. When opening a transaction we have some entity - a transaction object - which we need to pass to the adapter to perform database operations exactly within this transaction.
This is where the chicken and egg problem arises. On the one hand, the adapter requires that for each query within a transaction, information about that transaction itself must be passed - usually the library used implements the transaction as some kind of object through which queries can be made. On the other hand, the domain or application layer should not know about the adapter implementation in the hexagon paradigm. You can wrap the transaction in some interface, but this interface will be monstrously huge (with methods like Select, Insert, Delete and others - open your favorite SQL library and see how many methods there). And it will not make any sense to the domain - these methods will be used within the adapter, where there is a direct access to the transaction object without any abstraction.
We could go another way and pass the transaction as interface{} and then cast it to the desired type in the adapter via reflexion, but I consider this approach unserious and unsuitable for productive code. Besides, I don’t want to pollute method signature by passing an additional transaction object, because it doesn’t directly relate to the method itself. The transaction object a indicates the specifics of the whole process of working with the database as part of the operation. So what to do?
Specific Implementations Solution
Now a couple of words about the context of our solution. In my search for an elegant implementation, I have encountered several times solutions like UnitOfWork, representing a transaction as some business entity (which the business logic core knows about). Indeed, a transaction can be represented as some kind of business entity - after all, business logic can require atomic and non-competitive execution of a transaction. But the problem with elegant ideas is the inelegant implementation - abstract factories, reflexion, and messy handling of the methods of the adapter itself.
Often these complications are dictated by the desire to work with several databases, or to be able to switch from one database to another by changing only the adapter code (and without changing the business logic).
Realizing that this is too “abstract,” and in general does not meet the Go Way, I derived a few limitations of our project that were supposed to simplify this task:
- The service works with only one database;
- We use a particular library to work with the database.
The service works with only one database
And it’s PosgreSQL. Well really, how often do you switch between databases? Many people try to write some generic code to work with a generic SQL database, but does it make sense? The experience shows that switching from one SQL database to another will still force you to rework the entire project, and switching from SQL to NoSQL or vice versa is out of the question.
We use a particular library to work with the database
And it is go-pg. I personally really like it as a query builder (rather than an ORM) and it has good performance. It has one feature which I’ll tell you about next, without which I would have struggled to implement what I had in mind. But this feature is available in other libraries too, so don’t rush to rewrite your code.
What did we end up with
That’s why I took transactions in go-pg as the basis with a clear mind. I wanted to keep the repository method signatures clean (only the context and method call parameters), but also make the solution idiomatic from a Go perspective.
Golang has an excellent tool that allows you to pass utility data that doesn’t concern a particular method call, but concerns the context of an operation - context.Context. Often telemetry, loggers, idempotent identifiers, and other things go there. From my point of view transaction information perfectly fits the definition of “utility data” - it’s some kind of process modifier which doesn’t affect the logic directly but has an indirect effect. From words to deeds!
package postgres
import ...
type txKey struct{}
// injectTx injects transaction to context
func injectTx(ctx context.Context, tx *pg.Tx) context.Context {
return context.WithValue(ctx, txKey{}, tx)
}
// extractTx extracts transaction from context
func extractTx(ctx context.Context) *pg.Tx {
if tx, ok := ctx.Value(txKey{}).(*pg.Tx); ok {
return tx
}
return nil
}
The first step is to add methods to put the transaction object into the context and retrieve the transaction from the context. The methods are non-exportable, i.e. they can only be called inside the adapter. Note - a transaction from the go-pg package is used here without any wrappers or abstractions. We can afford it inside the adapter!
Next, we need to teach the adapter itself (the repository) how to work with a transaction. And this is where we need a feature that we have in go-pg, but not in some other libraries, such as sqlx. This is a single interface for query methods executed by the library, both in a transaction and without it. They are Select, Insert, Delete and others - they should have the same signature for transaction and non-transaction to be able to be taken out of the interface. If not, you have to write a wrapper. In case of go-pg both database connection object and the transaction object have method ModelContext(c context.Context, model ...interface{}) *Query which we used.
We got a little wrapper that checks if there is a transaction in the context. If there is - it returns Query from the transaction object, and if not - it returns Query from the database connection object.
package postgres
import ...
// model returns query model with context with or without transaction extracted from context
func (db *Database) model(ctx context.Context, model ...interface{}) *orm.Query {
tx := extractTx(ctx)
if tx != nil {
return tx.ModelContext(ctx, model...)
}
return db.conn.ModelContext(ctx, model...)
}
Database here is the actual structure that implements CarRepository, whose methods contain SQL queries to PostgreSQL, as well as a connection (or a connection pool) to the database. It can implement more repositories if you have a lot of them.
As a result, the method that reads cars from the database will look like this:
package postgres
import ...
func (db *Database) GetCarsByTimePeriod(ctx context.Context, from, to time.Time) ([]model.Car, error) {
var m []model.Car
err := db.model(ctx, &m).
Where("manufacture_date BETWEEN ? AND ?", from, to).
Order("model").
Select()
if err != nil {
return nil, err
}
return m, nil
}
Moreover, you can use a method with or without a transaction - neither the signature nor the method itself changes. And it is the part of the service with business logic that decides whether to use a transaction or not. Let’s see how this is done.
Transactions in Business and Business in Transactions
The only thing left is to implement a method to create a transaction inside the adapter, which would return the context “loaded” with transaction; add this method to the interface, and call it in business logic, obtaining the context with the transaction. And then pass that context to all repository calls, and commit or rollback at the end.
It sounds logical, but it’s kind of messy. Maybe Go has a more elegant tool?
And there is one! A closure. Let’s create a method that allows us to execute the whole transaction without having to leave our seat:
package postgres
import ...
// WithinTransaction runs function within transaction
//
// The transaction commits when function were finished without error
func (db *Database) WithinTransaction(ctx context.Context, tFunc func(ctx context.Context) error) error {
// begin transaction
tx, err := db.conn.Begin()
if err != nil {
return fmt.Errorf("begin transaction: %w", err)
}
defer func() {
// finalize transaction on panic, etc.
if errTx := tx.Close(); errTx != nil {
log.Printf("close transaction: %v", errTx)
}
}()
// run callback
err = tFunc(injectTx(ctx, tx))
if err != nil {
// if error, rollback
if errRollback := tx.Rollback(); errRollback != nil {
log.Printf("rollback transaction: %v", errRollback)
}
return err
}
// if no error, commit
if errCommit := tx.Commit(); errCommit != nil {
log.Printf("commit transaction: %v", errCommit)
}
return nil
}
The method takes a context and a function to be executed in a transaction. Based on the context, a new context is created with the transaction, and passed to the function. This also allows to interrupt the execution of the function when the parent context is cancelled - for example, when a graceful shutdown occurs.
Next, if the function is executed without errors, commit is executed, otherwise a rollback is executed and the error is returned from the method.
We’ll put this method in a separate port - isolation must be respected!
package port
import ...
// Transactor runs logic inside a single database transaction
type Transactor interface {
// WithinTransaction runs a function within a database transaction.
//
// Transaction is propagated in the context,
// so it is important to propagate it to underlying repositories.
// Function commits if error is nil, and rollbacks if not.
// It returns the same error.
WithinTransaction(context.Context, func(ctx context.Context) error) error
}
Let’s add it via DI to the domain:
package domain
import ...
type Car struct {
carRepo port.CarRepository
transactor port.Transactor
}
func NewCar(transactor port.Transactor, carRepo port.CarRepository) &Car {
return &Car{
carRepo: carRepo,
transactor: transactor,
}
}
This allows us to not worry about transactions within the business logic at all, and simplify transaction operations to the following:
package application
import ...
func (a *Application) BuyCar(ctx context.Context, carId, ownerId string, price int) error {
if err := a.validateBuyer(ctx, ownerId, price); err != nil {
return err
}
// read owner domain
car, err := a.readCar(ctx, carId)
if err != nil {
return err
}
return c.transactor.WithinTransaction(ctx, func(txCtx context.Context) error {
return car.Sell(txCtx, ownerId, price)
})
}
Here, transaction management is performed within the application layer.
package domain
import ...
func (c *Car) Sell(ctx context.Context, ownerId string, price int) error {
if err := c.validateBuyer(ctx, ownerId, price); err != nil {
return err
}
if err := c.validatePurchase(ctx, ownerId); err != nil {
return err
}
event := model.CarEvent{
CarId: c.model.Id,
Seller: c.model.Owner,
Buyer: ownerId,
Price: price,
SoldAt: time.Now()
}
if err := c.carRepo.UpsertCarHistoryEvent(ctx, event); err != nil {
return err
}
c.model.Owner = ownerId
c.model.UpdatedAt = time.Now()
if err := c.carRepo.UpsertCar(ctx, c.model); err != nil {
return err
}
log.Printf("car %s model % sold to %s for %d",
car.Id, car.Model, owner.Name, price)
return nil
}
Note that methods UpsertCarHistoryEvent and UpsertCar are executed in the same transaction, even though the domain layer does not own the it.
Comforting results
In the end, we got:
- simple mechanism for transaction execution in terms of the business logic layer;
- isolation of levels, abstractions do not leak;
- no reflection, all transaction work is typed and fault-tolerant;
- clean repository methods, no need to add a transaction to a signature;
- query methods are transaction agnostic - if there is a transaction, they are executed within it, if not - directly on the database;
- commit and rollback are executed automatically according to the function execution result. No deferring.
- in case of panic, rollback will be executed inside
tx.Close().
This approach is applicable to any database that supports ACID transactions, as long as there is a common interface for both in-transaction and out-of-transaction queries. If you wish, you can add your own wrapper if your favorite library doesn’t have it.
This approach is not applicable when you work with several databases in one service and you need to link two transactions into one. In this case, I do not envy you.
I may have departed from DDD principles or neglected the concepts of hexagonal architecture, but the result came out simple, beautiful and readable.
What would you do? Feel free to comment for ideas and critique!
comments