
Basics of cloud scaling
In this article, you will learn what application scaling is, and how cloud infrastructure simplifies the process and makes it more useful for business.
Scalability according to Wikipedia is the property of a system to handle a growing amount of work by adding resources to the system. In other words, it is the ability of the system to increase or decrease the amount of used resources (RAM, CPU, network bandwidth, disk size, etc.) depending on the load - the number of requests per second, the amount of stored data, computational load, etc.
When we talk about scaling, it’s worth starting with defining the system itself. A system can be either monolithic or distributed, and depending on this, the way it scales is different.
Scaling a Monolithic System
This type of system has existed for quite some time, and is the easiest to implement. Usually the application comes as an executable file or a set of scripts run by the server. It runs on a physical server or a virtual machine, often together with a database and a reverse-proxy like Nginx. Thus, networking problems in the interaction of components are minimized, and the system itself can be delivered as a virtual machine template or even as an installation disk.
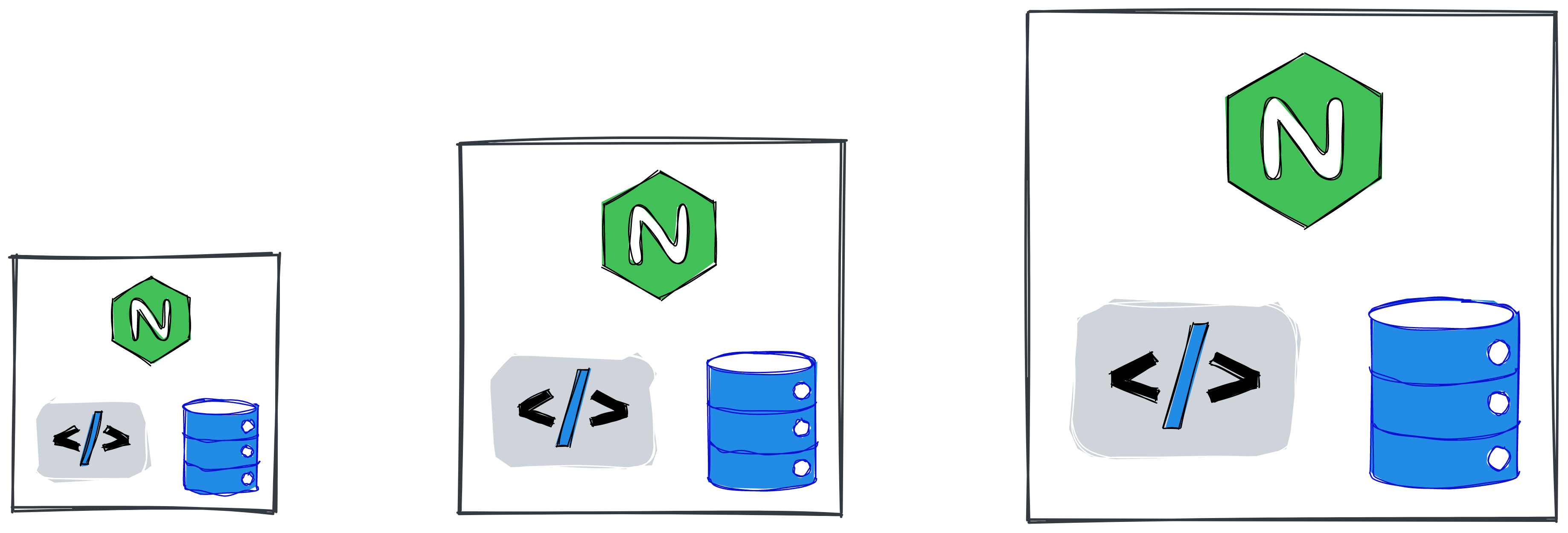
The approach to scaling such systems is vertical scaling - when the system runs out of resources, it restarts on a more powerful server with more resources.
This used to work well when manufacturers were releasing computers twice as powerful every six months. In recent decades, however, the rate of releases has decreased as microchip capabilities have approached their physical limit. Therefore, more powerful computers today are much more expensive than their less powerful counterparts. And doubling the capacity can increase the cost by 5 or even 10 times.
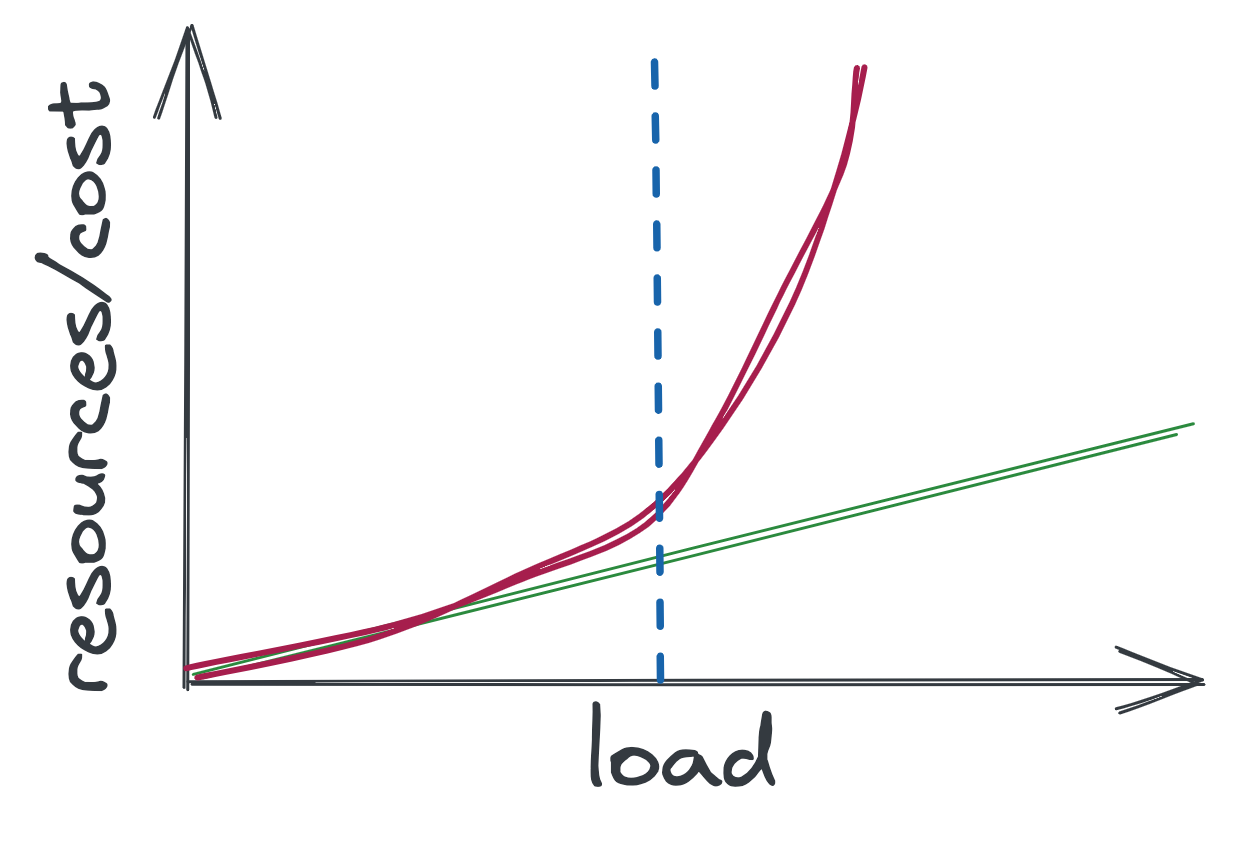
So when you reach a certain point, it simply becomes too expensive to buy a more powerful server. It is much more cost-effective to buy a lot of cheap computers, getting the total of the same resources. But to operate a system based on a fleet of individual machines, it must be distributed.
Scaling a Distributed System
The ability to scale the system is divided into three directions:
- horisontal duplication;
- functional decomposition;
- data partitioning.
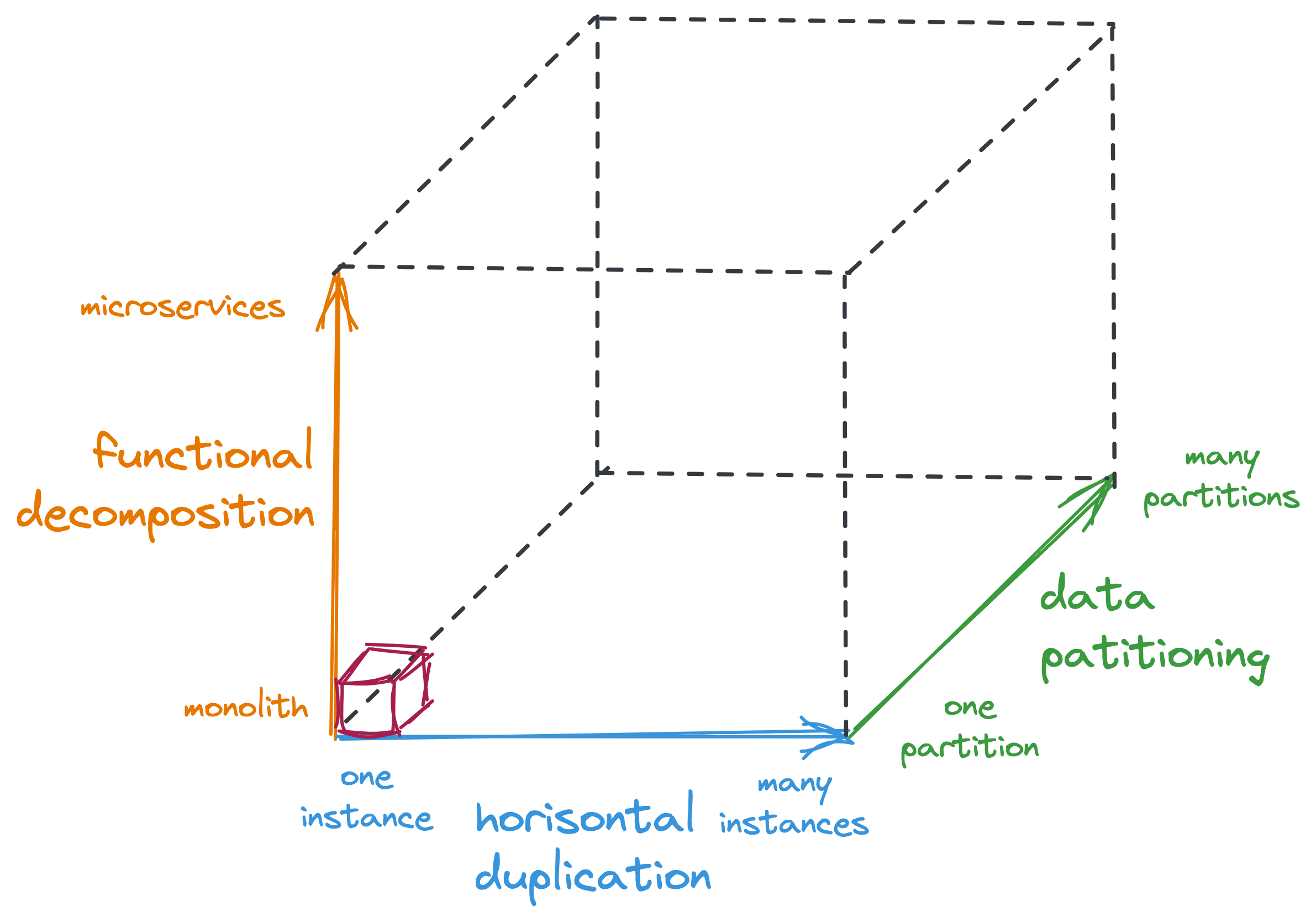
Let’s take a closer look.
Horisontal Duplication
Horisontal duplication is about running multiple copies of the same application in parallel. The copies have the same functionality, and are called replicas. In most cases the load is evenly distributed between replicas. To distribute requests between replicas, a load balancer is used, but that will be discussed in another article.

The more replicas a service has, the more resources are available to it. When resources become insufficient to handle the load on the system, it is sufficient to run several new replicas, and the excess load will be processed.
Horisontal duplication also helps to achieve increased service availability. In case one of the replicas becomes unavailable (application crash due to a bug, network problem, resource shortage and OOM Killer), the load will be distributed among the remaining replicas, and the load balancer will prevent data loss.
This approach is also called as horisontal scaling.
Functional Decomposition
In functional decomposition, system functionality is divided into separate components (e.g., microservices). Each domain of the system or part of the functionality is decoupled into a separate and independent service.
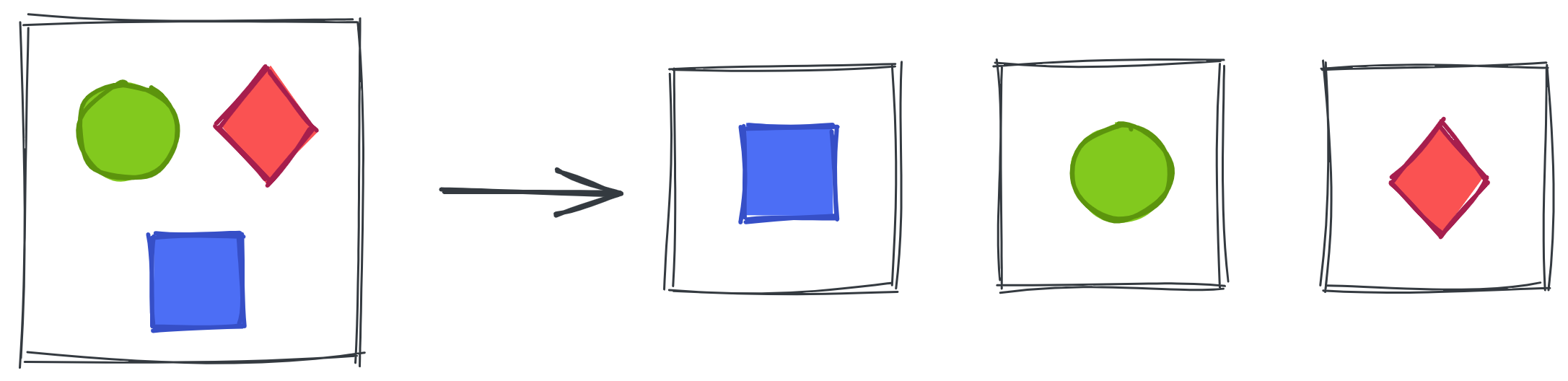
This makes it possible to isolate the logic of individual loosely coupled parts of the system. This simplifies the process of service development and delivery, and reduces the probability of mutual dependencies and blocking between development teams.
Teams become more independent - they can choose their own technologies and development tools, their own team collaboration frameworks (Scrum, Kanban, etc.), best suited to the nature of the application and the skills of team members. In doing so, the various services are no longer dependent on common parts of the application, libraries, or shared memory. They exchange data explicitly through APIs, so all that connects them to each other are synchronous and asynchronous message contracts.
Most importantly, functional decomposition allows each individual service to scale according to its needs. In the case of a monolithic system, the scalability of an individual component is very limited. In the case of a distributed system, one of the components can be run on multiple replicas, while the other will be run on a more powerful machine
Data Partitioning
Data partitioning is the splitting of stored data into several separate parts. For example, data stored in a single database is partitioned into several database instances, and finding a particular record in a particular database is determined by the partitioning key.
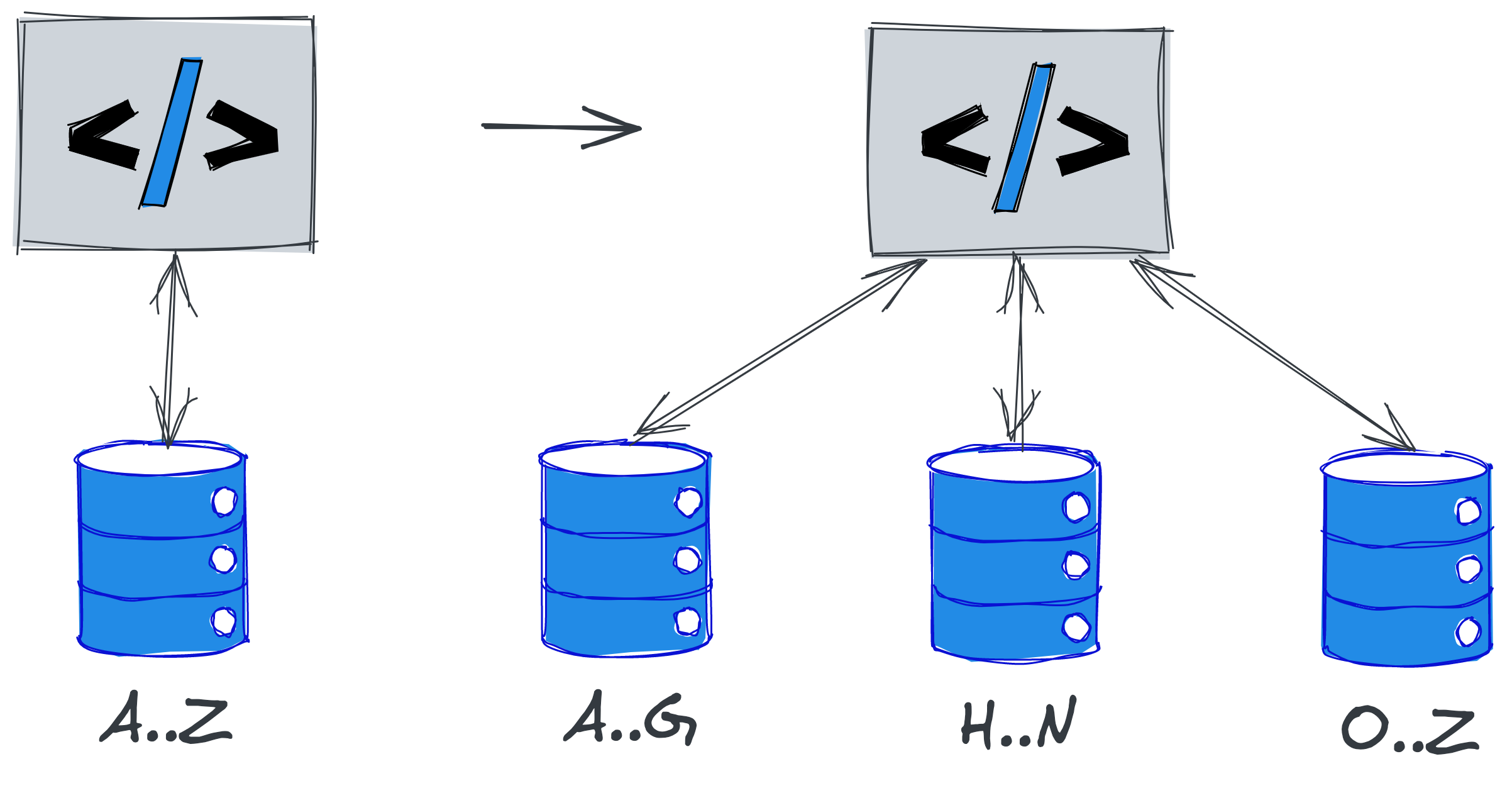
This way you can get around the limitation of storing data on a disk - the maximum disk size is physically limited, and when the amount of data exceeds its size, partitioning allows you to divide the data among several disks and thus store more data.
Another possibility of data partitioning is to distribute the query processing load among several databases. Typically, a database is a complex application that consumes a fair amount of CPU and RAM. As the number of queries or their complexity increases, the database consumes more and more resources. Data partitioning allows you to have more database instances, and therefore have more computing resources available to perform queries.
Cloud Benefit of Scaling
Cloud platforms, unlike the bare metal or virtual machines available in conventional hosting, offer a simple infrastructure management option. For example, an administrator can configure the cloud infrastructure through a simple web interface, or through a CLI application, or via an API.
It also provides a wide range of options for automating infrastructure management. From routine tasks automation through simple scripts using the CLI, to implementing the Infrastructure-as-a-Code approach using tools like Terraform.
Finally, clouds also offer built-in infrastructure management solutions, such as automatic scaling (including smart self-learning autoscaling in the largest clouds). These tools allow you to spend less time configuring infrastructure so you can use it to grow your product.
In the following articles, I will talk about specific cloud scaling options and teach you how to set up an autoscalable system by yourself.
comments